1) RecSys Level 2 대회 - DKT 4주차
드디어 오늘부로 대회가 끝났다! 이번주는 코딩 .. 실험.. 그리고 실험..의 반복이었던 것 같다. ㅎㅎ
한 달간의 대회가 끝나 후련하기도, 아쉽기도 하다. 이번 대회를 통해 나의 부족함을 많이 깨달았다.
하지만 좌절하는 게 아니라 이제부터 개선해 나가면 된다! 이번 대회에서의 경험이 앞으로의 성장의 밑거름이 될 거라 믿는다.
Cross-Validation
저번주 Cross Validation 작업을 맡아 sklearn 모듈을 활용해 1차적으로 구현을 완료했으나, 대회의 데이터 형식과 일치하도록 하려면, user 기준으로 split해야 했다. 하지만, user 기반 split 기능은 이미 초반에 빠르게 구현하지 못해서 한 번 포기했던 상태이고, 내 지식과 능력으로는 또 시간만 끌게 될 것 같아.. 팀 차원에서도 개인 차원에서도 다른 작업을 하는 것이 좋을 것 같다고 판단했다.
CV 작업을 하면서 아쉬웠던 점은 다음과 같다.
CV 코드를 처음부터 끝까지, 기존에 있던 스크립트 파일상에 짜 보는 것이 처음이라 헷갈리고 어려운 부분이 많았다.
이론에 대해서도 대략적으로만 알고 있었고, 데이터도 거의 다뤄보지 않았던 sequential data였기 때문에 코드 작업 전 기본적인 내용들을 파악하는 데만 시간이 꽤 들었다.
그런데 이 작업을 혼자 맡게 되었다. 예전에 데이터만 모듈 내장 함수에 잘 넣어주면 뚝딱 나왔었기 때문에,, 어렵지 않을 거라 생각해서 "제가 CV 해보겠습니다!!" 하고 외쳐 맡게 된 작업이었는데, 하다보니 나의 능력으로는 그리 간단하진 않은 일이었다.
이때 후회되는 것은 다른 팀원들과 질문 및 소통을 많이 하지 못한 것이다.
좀 막히면 찿아가서 질문하고, 소통했다면 더 빠르게 끝낼 수 있었을텐데, 배워가는 것도 더 많았을텐데,
팀 차원에서도 내 상황을 파악할 수 있고, 도와줄 수 있어 좋았을텐데, .. 지나고서야 깨달았다.
'다른 팀원들도 바쁠텐데.' 라는 생각에 최대한 혼자 해결하려 했던 게 너무 컸다.
그러다보니 작업 속도도 생각보다 엄청 느려졌다. 총 하루 이틀 정도 걸릴 거라 생각했는데, 3일에 걸쳐 완성했다.
결과적으로 실수도 하나 나왔다.
각 fold를 돌고난 후 전체 데이터에 대해 한 번 더 모델을 학습시키는 것이 성능 향상에 도움이 된다는 정보를 ChatGPT로부터 알게 되어, 그 형식으로 CV 코드를 구현했다. 그런데 그렇게 넘긴 코드로 돌렸을 때 엄청난 과적합이 발생했다는 사실을 들었고, ..
ChatGPT가 항상 옳은 건 아니라는 걸 다시 한 번 깨달았다. 사실 안쓰려던 방식인데, ChatGPT가 계속 그렇게 코드를 보여주길래 굳~이 굳이 마지막에 추가한 것이었다. 이때 한 번 그냥 다른 팀원 분께 여쭈어 봤다면 비용을 절약할 수 있었을 것이다.
구체적인 회고는 아래 3) 학습 회고 에서 자세히..!
OOF Stacking Ensemble
CV 1차 작업을 끝내니 어느덧 대회 3주차에 접어들었다.
그동안 모델 쪽을 항상 깊게 다루지 못해봐서 모델 쪽을 다뤄보기로 했다.
다른 팀원 분이 감사하게도 CV 2차 작업을 뒤이어 해주셨고, 나는 이번주부터 OOF Stacking Ensemble 작업을 하게 되었다.
OOF (Out Of Fold) 란 무엇인가?

Cross-Validation에서 각 fold마다 validation set의 예측값들을 모아 새로운 데이터셋(핑크색)을 만드는 것을 OOF라고 한다. 이 새로운 데이터셋을 메타 모델의 train 데이터셋으로 사용한다.
밑은 test에서의 OOF로, 각 fold에서 훈련된 모델들로 test 데이터셋을 예측해 평균을 내는 것을 말한다. 이는 메타 모델의 test set으로 사용한다.
그렇다면 OOF Stacking은?
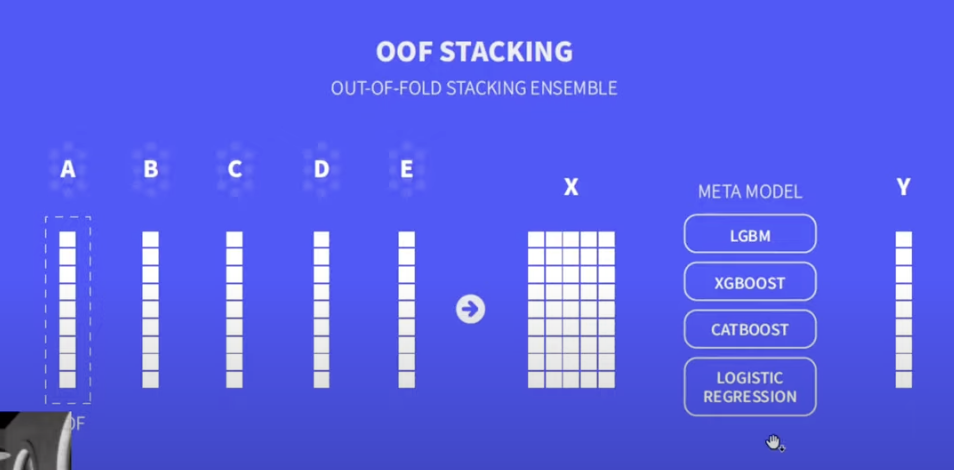
우선 stacking이란 모델의 결과를 다시 앙상블 하는 기법을 의미한다.
모델이 예측한 y_pred 값과 실제 y_true 값은 매우 강한 선형성을 띄게 된다는 사실을 이용하는 것이다.
OOF Stacking은,
각 모델(A, B, ...)마다 OOF를 구현해서 예측값(모델마다 한 컬럼)을 뽑아내고,
각 모델의 예측값들을 concat, 즉 stacking 해서 하나의 새로운 데이터셋(X)으로 만든 후,
이 X를 meta model에 넣어 훈련시켜 최종 예측(Y)을 뽑아 내는 것이다.

대회를 진행하며, 기초 지식이 부족한만큼 공부량이 정말 많이 필요하다는 것을 느꼈다.
이전까지 이론 공부를 깊이 하지 못하고 잊어버린 부분이 많아서 아쉬움이 계속 있었다.
다음 대회부터는 더 철저히 복습하고 꼼꼼히 공부해나가며 대회를 진행해야겠다고 다짐했다!
그래도 이번 대회를 통해, 전체적인 프로젝트 그림을 그려볼 수 있었다.
저번 대회에서는 데이터를 위주로 다루다보니 전체적인 그림을 잘 그리지 못했었는데,
이번 대회에서는 어떤 과정을 거치는지, 그리고 각 과정에서 어떠한 것들을 수행하는지 전체적으로 조금씩 경험해볼 수 있었다.
무엇보다, 정말 좋은 팀을 만나 협업이 무엇인지 아주 제대로 알아가는 것 같다 !
2) 피어세션
나는 이번주 모더레이터를 맡아 데일리스크럼과 피어세션 진행을 맡았다.
사실 대회 마지막 주라, 어제 오늘은 PM 님의 지도가 더욱 컸던 것 같지만 ㅎㅎ
내가 모더레이터를 시작하며 잡은 하나의 소소한 목표는, 회의를 정해진 시간 안에 최대한 완료하는 것이다.
멘토 님께서 회의 시간이 길다고 좋은 게 아니라고 조언을 듣기도 했고, 대회 마지막 주인만큼 개인 작업 시간도 확보하기 위해 회의를 너무 길게 하지 않으려고 한 것 같다.
길어지면 팀원들에게 얘기하고 통제(?)해보려 했으나, 다행히 대부분 알아서 1시간 이내 잘 끝난 것 같다.
더 길 때도 있었지만, 대회 이야기는 어쩔 수 없다. ㅎㅎ
재밌는 팀원들 덕분에 긴 회의도 그닥 힘들지 않고 재밌게 하고 있다!
남은 하루도 모더레이터로서 마무리 잘 해 보자 ~~!
3) 학습 회고
이번 협업을 통해 깨달은 것은, 내가 그리도 중요하게 생각해 오던 '소통'을 만족할만큼 썩 잘 하진 못했다는 것이다.
그리고 그 소통의 기반은 '문서화'라는 것도 느꼈다.
1. 작업을 시작하기 전, 수행할 작업을 문서화하여 공유해야 한다.
- 큰 그림을 그려보고, 가능하다면 작업을 쪼개서 작은 작업 단위로 단계적으로 표현할 것. (Github Issue, Notion 활용)
- 어떤 작업이 주어지면, 그 작업에 소요될 예상 시간과 계획을 공유할 것.
- 당장 예상이 안된다면 양해를 구해 1시간 안에 파악 & 결론 내기!
2. 모르고 헷갈리는 건 혼자 고민하는 게 아니라 '같이' 고민하자.
- 실수를 막는 예방책이다!
3. 이해가 가지 않는 것은 한 번 더 질문해 완전히 파악하고 넘어가자.
- 애매하게만 이해 된다면 한 번 더 설명 부탁드려서 완전히 파악하기!
- 애매하게 파악하는 과정이 쌓이고 쌓이다보면,,, 나중에는 뭘 하는지 모르게 된다.
알아도 매번 실천하기 쉽지 않을 거라 생각한다. 항상 머릿속에 상기하여 최대한 지켜보자 !
그래도 뭐든 열심히 하려 노력한 것 같고, 팀원 분들이 정말 잘 이끌어주셔서 너무너무 감사하고 좋았다! 우리 팀 최고,,, 다음 프로젝트가 더욱 더 기대된다!
다음 대회도 화이팅!!!!!!
'NAVER boostcamp AI Tech' 카테고리의 다른 글
| [NAVER boostcamp AI Tech 5기] 14주차 학습 정리 (1) | 2023.06.09 |
|---|---|
| [NAVER boostcamp AI Tech 5기] 13주차 학습 정리 (0) | 2023.06.02 |
| [NAVER boostcamp AI Tech 5기] 11주차 학습 정리 (0) | 2023.05.19 |
| [NAVER boostcamp AI Tech 5기] 10주차 학습 정리 (0) | 2023.05.10 |
| [NAVER boostcamp AI Tech 5기] 9주차 학습 정리 (0) | 2023.05.04 |